02 Creating a histogram
Contents
02 Creating a histogram#
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import plotly.graph_objects as go
import seaborn as sns
import findspark
findspark.init()
from pyspark.context import SparkContext
from pyspark.sql import functions as F
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.appName("statistics").master("local").getOrCreate()
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/home/runner/work/statistics/spark-3.1.3-bin-hadoop3.2/jars/spark-unsafe_2.12-3.1.3.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
22/07/21 02:33:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
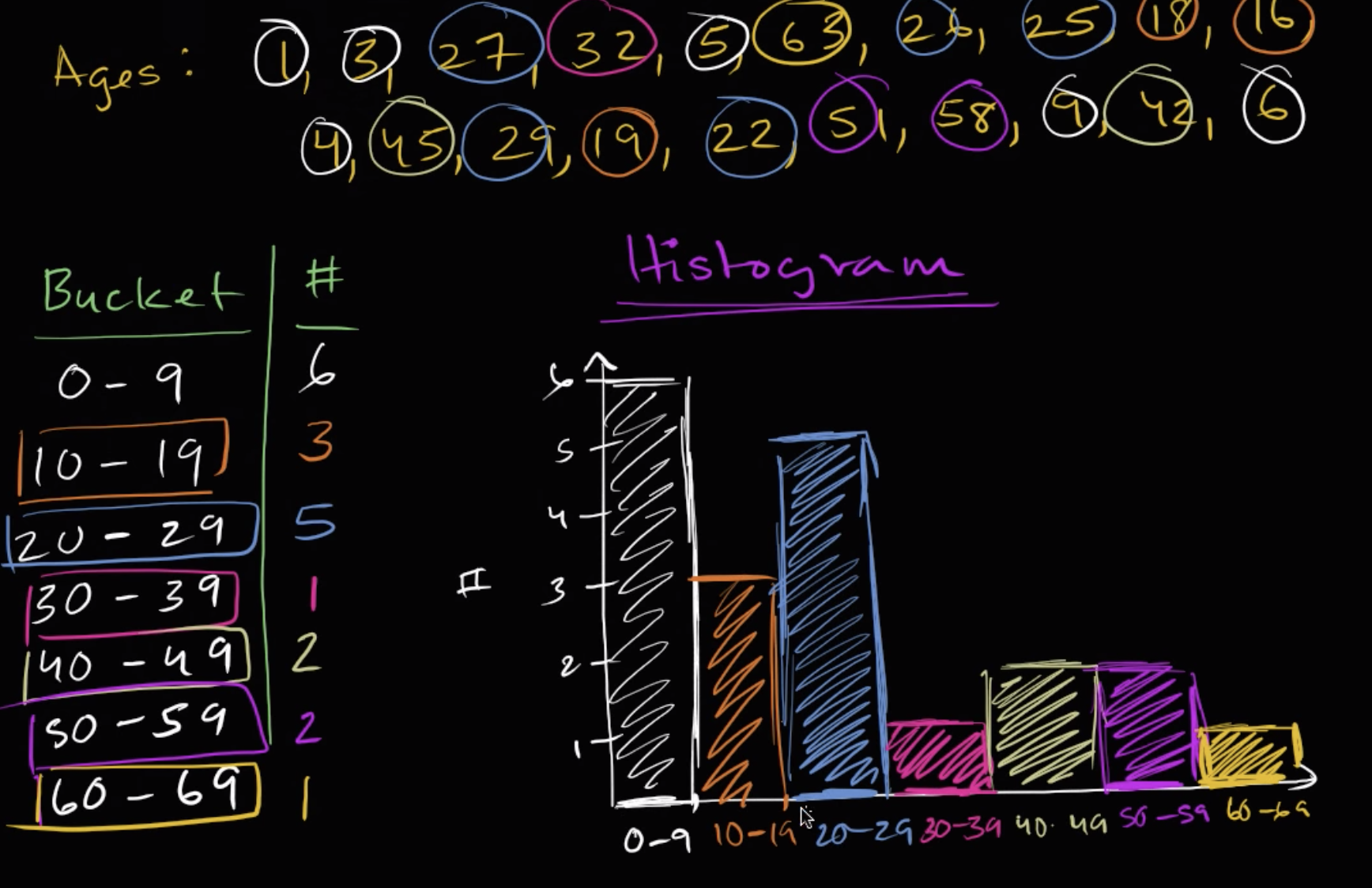
ages = np.array(
[1, 3, 27, 32, 5, 63, 26, 25, 18, 16, 4, 45, 29, 19, 22, 51, 58, 9, 42, 6]
)
Generating dataset using for loop#
buckets = ["0-9", "10-19", "20-29", "30-39", "40-49", "50-59", "60-69"]
ages_list = []
for i in buckets:
min_, max_ = i.split("-")
get_ages = ages[(ages >= int(min_)) & (ages <= int(max_))]
ages_list.append(len(get_ages))
dataset = {"Buckets": buckets, "#": ages_list}
Pandas#
df = pd.DataFrame(dataset)
df
| Buckets | # | |
|---|---|---|
| 0 | 0-9 | 6 |
| 1 | 10-19 | 3 |
| 2 | 20-29 | 5 |
| 3 | 30-39 | 1 |
| 4 | 40-49 | 2 |
| 5 | 50-59 | 2 |
| 6 | 60-69 | 1 |
Spark#
sdf = spark.createDataFrame(zip(*dataset.values()), schema=list(dataset.keys()))
sdf.show()
[Stage 0:> (0 + 1) / 1]
+-------+---+
|Buckets| #|
+-------+---+
| 0-9| 6|
| 10-19| 3|
| 20-29| 5|
| 30-39| 1|
| 40-49| 2|
| 50-59| 2|
| 60-69| 1|
+-------+---+
Generating dataset using np histogram#
bins = np.arange(0, 80, 10)
ages_list, buckets = np.histogram(ages, bins)
dataset = {"Buckets": buckets[1:].tolist(), "#": ages_list.tolist()}
Pandas#
df = pd.DataFrame(dataset)
df
| Buckets | # | |
|---|---|---|
| 0 | 10 | 6 |
| 1 | 20 | 3 |
| 2 | 30 | 5 |
| 3 | 40 | 1 |
| 4 | 50 | 2 |
| 5 | 60 | 2 |
| 6 | 70 | 1 |
Spark#
sdf = spark.createDataFrame(zip(*dataset.values()), list(dataset.keys()))
sdf.show()
+-------+---+
|Buckets| #|
+-------+---+
| 10| 6|
| 20| 3|
| 30| 5|
| 40| 1|
| 50| 2|
| 60| 2|
| 70| 1|
+-------+---+
Histogram#
Matplotlib#
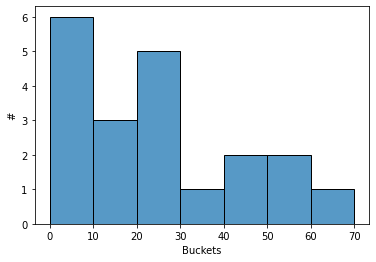
n, bins, _ = plt.hist(ages, buckets)
plt.xlabel("Buckets")
plt.ylabel("#")
plt.show()

print(n, bins)
[6. 3. 5. 1. 2. 2. 1.] [ 0 10 20 30 40 50 60 70]
Seanorn#
sns.histplot(ages, bins=buckets)
plt.xlabel("Buckets")
plt.ylabel("#")
plt.show()
Plotly#
data = [
go.Histogram(
x=ages,
nbinsx=7,
marker=dict(
color=[
"lightyellow",
"darkorange",
"cornflowerblue",
"magenta",
"lightgreen",
"darkviolet",
"yellow",
]
),
)
]
layout = go.Layout(xaxis=dict(title="bucket"), yaxis=dict(title="#"))
fig = go.Figure(data, layout)
fig.show()