01 Identifying individuals, variables and categorical variables in a data set
Contents
01 Identifying individuals, variables and categorical variables in a data set#
%%html
<iframe width="700" height="400" src="https://www.youtube.com/embed/EqeVXI4WNHM/" frameborder="0" allowfullscreen></iframe>
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import plotly.graph_objects as go
import seaborn as sns
from sklearn import preprocessing
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.1.3,org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.3 pyspark-shell'
import findspark
findspark.init()
from pyspark.context import SparkContext
from pyspark.ml.feature import OneHotEncoder, StringIndexer
from pyspark.sql import functions as F
from pyspark.sql.types import *
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.appName("statistics").master("local").getOrCreate()
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/home/runner/work/statistics/spark-3.1.3-bin-hadoop3.2/jars/spark-unsafe_2.12-3.1.3.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
:: loading settings :: url = jar:file:/home/runner/work/statistics/spark-3.1.3-bin-hadoop3.2/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /home/runner/.ivy2/cache
The jars for the packages stored in: /home/runner/.ivy2/jars
org.apache.spark#spark-streaming-kafka-0-10_2.12 added as a dependency
org.apache.spark#spark-sql-kafka-0-10_2.12 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-c033a962-35bf-4f50-9652-48dfb32daf16;1.0
confs: [default]
found org.apache.spark#spark-streaming-kafka-0-10_2.12;3.1.3 in central
found org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.1.3 in central
found org.apache.kafka#kafka-clients;2.6.0 in central
found com.github.luben#zstd-jni;1.4.8-1 in central
found org.lz4#lz4-java;1.7.1 in central
found org.xerial.snappy#snappy-java;1.1.8.2 in central
found org.slf4j#slf4j-api;1.7.30 in central
found org.spark-project.spark#unused;1.0.0 in central
found org.apache.spark#spark-sql-kafka-0-10_2.12;3.1.3 in central
found org.apache.commons#commons-pool2;2.6.2 in central
downloading https://repo1.maven.org/maven2/org/apache/spark/spark-streaming-kafka-0-10_2.12/3.1.3/spark-streaming-kafka-0-10_2.12-3.1.3.jar ...
[SUCCESSFUL ] org.apache.spark#spark-streaming-kafka-0-10_2.12;3.1.3!spark-streaming-kafka-0-10_2.12.jar (21ms)
downloading https://repo1.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.12/3.1.3/spark-sql-kafka-0-10_2.12-3.1.3.jar ...
[SUCCESSFUL ] org.apache.spark#spark-sql-kafka-0-10_2.12;3.1.3!spark-sql-kafka-0-10_2.12.jar (49ms)
downloading https://repo1.maven.org/maven2/org/apache/spark/spark-token-provider-kafka-0-10_2.12/3.1.3/spark-token-provider-kafka-0-10_2.12-3.1.3.jar ...
[SUCCESSFUL ] org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.1.3!spark-token-provider-kafka-0-10_2.12.jar (8ms)
downloading https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.6.0/kafka-clients-2.6.0.jar ...
[SUCCESSFUL ] org.apache.kafka#kafka-clients;2.6.0!kafka-clients.jar (145ms)
downloading https://repo1.maven.org/maven2/org/spark-project/spark/unused/1.0.0/unused-1.0.0.jar ...
[SUCCESSFUL ] org.spark-project.spark#unused;1.0.0!unused.jar (4ms)
downloading https://repo1.maven.org/maven2/com/github/luben/zstd-jni/1.4.8-1/zstd-jni-1.4.8-1.jar ...
[SUCCESSFUL ] com.github.luben#zstd-jni;1.4.8-1!zstd-jni.jar (181ms)
downloading https://repo1.maven.org/maven2/org/lz4/lz4-java/1.7.1/lz4-java-1.7.1.jar ...
[SUCCESSFUL ] org.lz4#lz4-java;1.7.1!lz4-java.jar (25ms)
downloading https://repo1.maven.org/maven2/org/xerial/snappy/snappy-java/1.1.8.2/snappy-java-1.1.8.2.jar ...
[SUCCESSFUL ] org.xerial.snappy#snappy-java;1.1.8.2!snappy-java.jar(bundle) (57ms)
downloading https://repo1.maven.org/maven2/org/slf4j/slf4j-api/1.7.30/slf4j-api-1.7.30.jar ...
[SUCCESSFUL ] org.slf4j#slf4j-api;1.7.30!slf4j-api.jar (5ms)
downloading https://repo1.maven.org/maven2/org/apache/commons/commons-pool2/2.6.2/commons-pool2-2.6.2.jar ...
[SUCCESSFUL ] org.apache.commons#commons-pool2;2.6.2!commons-pool2.jar (6ms)
:: resolution report :: resolve 3089ms :: artifacts dl 511ms
:: modules in use:
com.github.luben#zstd-jni;1.4.8-1 from central in [default]
org.apache.commons#commons-pool2;2.6.2 from central in [default]
org.apache.kafka#kafka-clients;2.6.0 from central in [default]
org.apache.spark#spark-sql-kafka-0-10_2.12;3.1.3 from central in [default]
org.apache.spark#spark-streaming-kafka-0-10_2.12;3.1.3 from central in [default]
org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.1.3 from central in [default]
org.lz4#lz4-java;1.7.1 from central in [default]
org.slf4j#slf4j-api;1.7.30 from central in [default]
org.spark-project.spark#unused;1.0.0 from central in [default]
org.xerial.snappy#snappy-java;1.1.8.2 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 10 | 10 | 10 | 0 || 10 | 10 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-c033a962-35bf-4f50-9652-48dfb32daf16
confs: [default]
10 artifacts copied, 0 already retrieved (13222kB/34ms)
22/07/21 02:30:31 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
import json
import uuid
from confluent_kafka import Producer
from ksql import KSQLAPI
bootstrap_servers='[::1]:9092'
topic=f'stats0101{str(uuid.uuid4())[:7]}'
msg_count=5
client = KSQLAPI(url='http://localhost:8088')
---------------------------------------------------------------------------
ConnectionRefusedError Traceback (most recent call last)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/connection.py:174, in HTTPConnection._new_conn(self)
173 try:
--> 174 conn = connection.create_connection(
175 (self._dns_host, self.port), self.timeout, **extra_kw
176 )
178 except SocketTimeout:
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/util/connection.py:95, in create_connection(address, timeout, source_address, socket_options)
94 if err is not None:
---> 95 raise err
97 raise socket.error("getaddrinfo returns an empty list")
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/util/connection.py:85, in create_connection(address, timeout, source_address, socket_options)
84 sock.bind(source_address)
---> 85 sock.connect(sa)
86 return sock
ConnectionRefusedError: [Errno 111] Connection refused
During handling of the above exception, another exception occurred:
NewConnectionError Traceback (most recent call last)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/connectionpool.py:703, in HTTPConnectionPool.urlopen(self, method, url, body, headers, retries, redirect, assert_same_host, timeout, pool_timeout, release_conn, chunked, body_pos, **response_kw)
702 # Make the request on the httplib connection object.
--> 703 httplib_response = self._make_request(
704 conn,
705 method,
706 url,
707 timeout=timeout_obj,
708 body=body,
709 headers=headers,
710 chunked=chunked,
711 )
713 # If we're going to release the connection in ``finally:``, then
714 # the response doesn't need to know about the connection. Otherwise
715 # it will also try to release it and we'll have a double-release
716 # mess.
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/connectionpool.py:398, in HTTPConnectionPool._make_request(self, conn, method, url, timeout, chunked, **httplib_request_kw)
397 else:
--> 398 conn.request(method, url, **httplib_request_kw)
400 # We are swallowing BrokenPipeError (errno.EPIPE) since the server is
401 # legitimately able to close the connection after sending a valid response.
402 # With this behaviour, the received response is still readable.
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/connection.py:239, in HTTPConnection.request(self, method, url, body, headers)
238 headers["User-Agent"] = _get_default_user_agent()
--> 239 super(HTTPConnection, self).request(method, url, body=body, headers=headers)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/http/client.py:1285, in HTTPConnection.request(self, method, url, body, headers, encode_chunked)
1284 """Send a complete request to the server."""
-> 1285 self._send_request(method, url, body, headers, encode_chunked)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/http/client.py:1331, in HTTPConnection._send_request(self, method, url, body, headers, encode_chunked)
1330 body = _encode(body, 'body')
-> 1331 self.endheaders(body, encode_chunked=encode_chunked)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/http/client.py:1280, in HTTPConnection.endheaders(self, message_body, encode_chunked)
1279 raise CannotSendHeader()
-> 1280 self._send_output(message_body, encode_chunked=encode_chunked)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/http/client.py:1040, in HTTPConnection._send_output(self, message_body, encode_chunked)
1039 del self._buffer[:]
-> 1040 self.send(msg)
1042 if message_body is not None:
1043
1044 # create a consistent interface to message_body
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/http/client.py:980, in HTTPConnection.send(self, data)
979 if self.auto_open:
--> 980 self.connect()
981 else:
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/connection.py:205, in HTTPConnection.connect(self)
204 def connect(self):
--> 205 conn = self._new_conn()
206 self._prepare_conn(conn)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/connection.py:186, in HTTPConnection._new_conn(self)
185 except SocketError as e:
--> 186 raise NewConnectionError(
187 self, "Failed to establish a new connection: %s" % e
188 )
190 return conn
NewConnectionError: <urllib3.connection.HTTPConnection object at 0x7fc92b7b0430>: Failed to establish a new connection: [Errno 111] Connection refused
During handling of the above exception, another exception occurred:
MaxRetryError Traceback (most recent call last)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/requests/adapters.py:489, in HTTPAdapter.send(self, request, stream, timeout, verify, cert, proxies)
488 if not chunked:
--> 489 resp = conn.urlopen(
490 method=request.method,
491 url=url,
492 body=request.body,
493 headers=request.headers,
494 redirect=False,
495 assert_same_host=False,
496 preload_content=False,
497 decode_content=False,
498 retries=self.max_retries,
499 timeout=timeout,
500 )
502 # Send the request.
503 else:
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/connectionpool.py:787, in HTTPConnectionPool.urlopen(self, method, url, body, headers, retries, redirect, assert_same_host, timeout, pool_timeout, release_conn, chunked, body_pos, **response_kw)
785 e = ProtocolError("Connection aborted.", e)
--> 787 retries = retries.increment(
788 method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]
789 )
790 retries.sleep()
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/urllib3/util/retry.py:592, in Retry.increment(self, method, url, response, error, _pool, _stacktrace)
591 if new_retry.is_exhausted():
--> 592 raise MaxRetryError(_pool, url, error or ResponseError(cause))
594 log.debug("Incremented Retry for (url='%s'): %r", url, new_retry)
MaxRetryError: HTTPConnectionPool(host='localhost', port=8088): Max retries exceeded with url: /info (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fc92b7b0430>: Failed to establish a new connection: [Errno 111] Connection refused'))
During handling of the above exception, another exception occurred:
ConnectionError Traceback (most recent call last)
Input In [4], in <cell line: 8>()
6 topic=f'stats0101{str(uuid.uuid4())[:7]}'
7 msg_count=5
----> 8 client = KSQLAPI(url='http://localhost:8088')
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/ksql/client.py:19, in KSQLAPI.__init__(self, url, max_retries, check_version, **kwargs)
17 self.sa = SimplifiedAPI(url, max_retries=max_retries, **kwargs)
18 if check_version is True:
---> 19 self.get_ksql_version()
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/ksql/client.py:29, in KSQLAPI.get_ksql_version(self)
28 def get_ksql_version(self):
---> 29 r = self.sa.get_request(self.url + "/info")
30 if r.status_code == 200:
31 info = r.json().get("KsqlServerInfo")
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/ksql/api.py:133, in BaseAPI.get_request(self, endpoint)
131 def get_request(self, endpoint):
132 auth = (self.api_key, self.secret) if self.api_key or self.secret else None
--> 133 return requests.get(endpoint, headers=self.headers, auth=auth)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/requests/api.py:73, in get(url, params, **kwargs)
62 def get(url, params=None, **kwargs):
63 r"""Sends a GET request.
64
65 :param url: URL for the new :class:`Request` object.
(...)
70 :rtype: requests.Response
71 """
---> 73 return request("get", url, params=params, **kwargs)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/requests/api.py:59, in request(method, url, **kwargs)
55 # By using the 'with' statement we are sure the session is closed, thus we
56 # avoid leaving sockets open which can trigger a ResourceWarning in some
57 # cases, and look like a memory leak in others.
58 with sessions.Session() as session:
---> 59 return session.request(method=method, url=url, **kwargs)
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/requests/sessions.py:587, in Session.request(self, method, url, params, data, headers, cookies, files, auth, timeout, allow_redirects, proxies, hooks, stream, verify, cert, json)
582 send_kwargs = {
583 "timeout": timeout,
584 "allow_redirects": allow_redirects,
585 }
586 send_kwargs.update(settings)
--> 587 resp = self.send(prep, **send_kwargs)
589 return resp
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/requests/sessions.py:701, in Session.send(self, request, **kwargs)
698 start = preferred_clock()
700 # Send the request
--> 701 r = adapter.send(request, **kwargs)
703 # Total elapsed time of the request (approximately)
704 elapsed = preferred_clock() - start
File /opt/hostedtoolcache/Python/3.9.13/x64/lib/python3.9/site-packages/requests/adapters.py:565, in HTTPAdapter.send(self, request, stream, timeout, verify, cert, proxies)
561 if isinstance(e.reason, _SSLError):
562 # This branch is for urllib3 v1.22 and later.
563 raise SSLError(e, request=request)
--> 565 raise ConnectionError(e, request=request)
567 except ClosedPoolError as e:
568 raise ConnectionError(e, request=request)
ConnectionError: HTTPConnectionPool(host='localhost', port=8088): Max retries exceeded with url: /info (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fc92b7b0430>: Failed to establish a new connection: [Errno 111] Connection refused'))
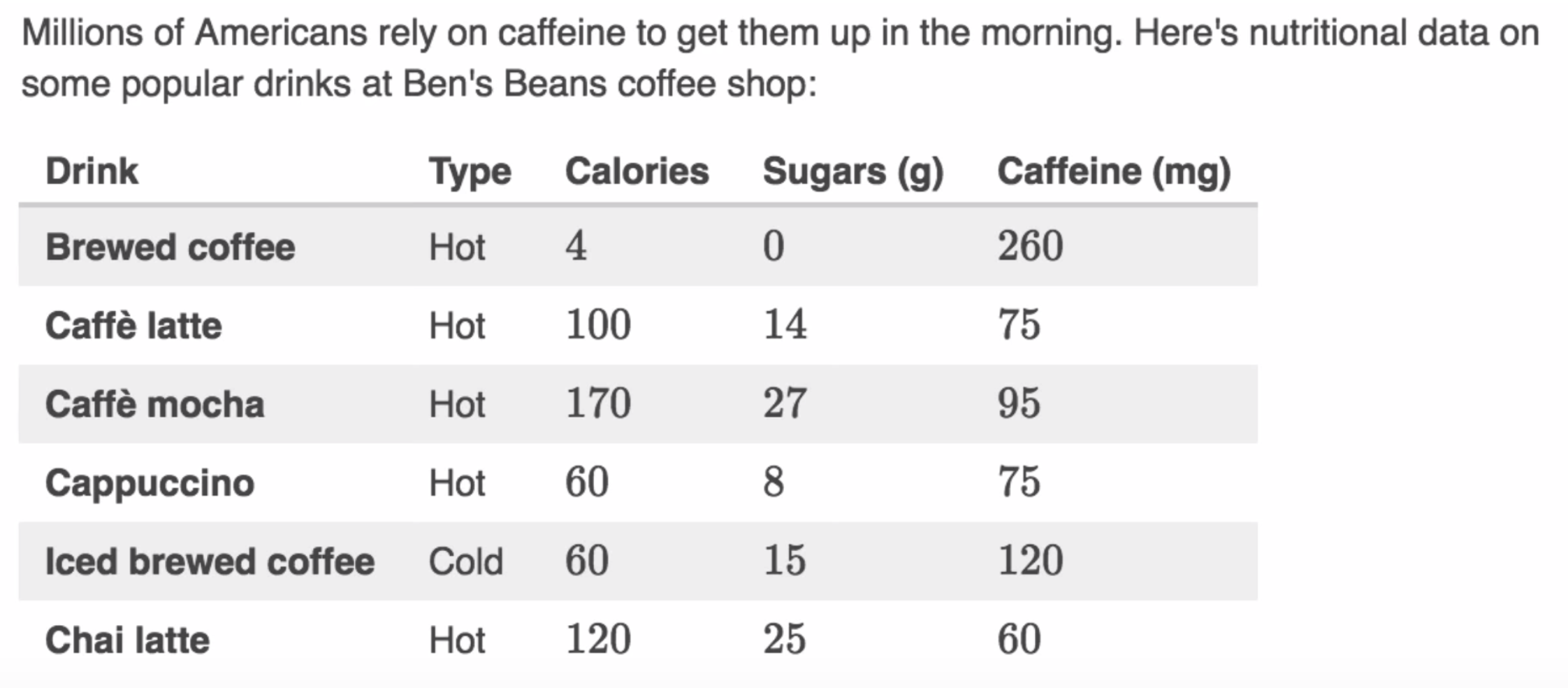
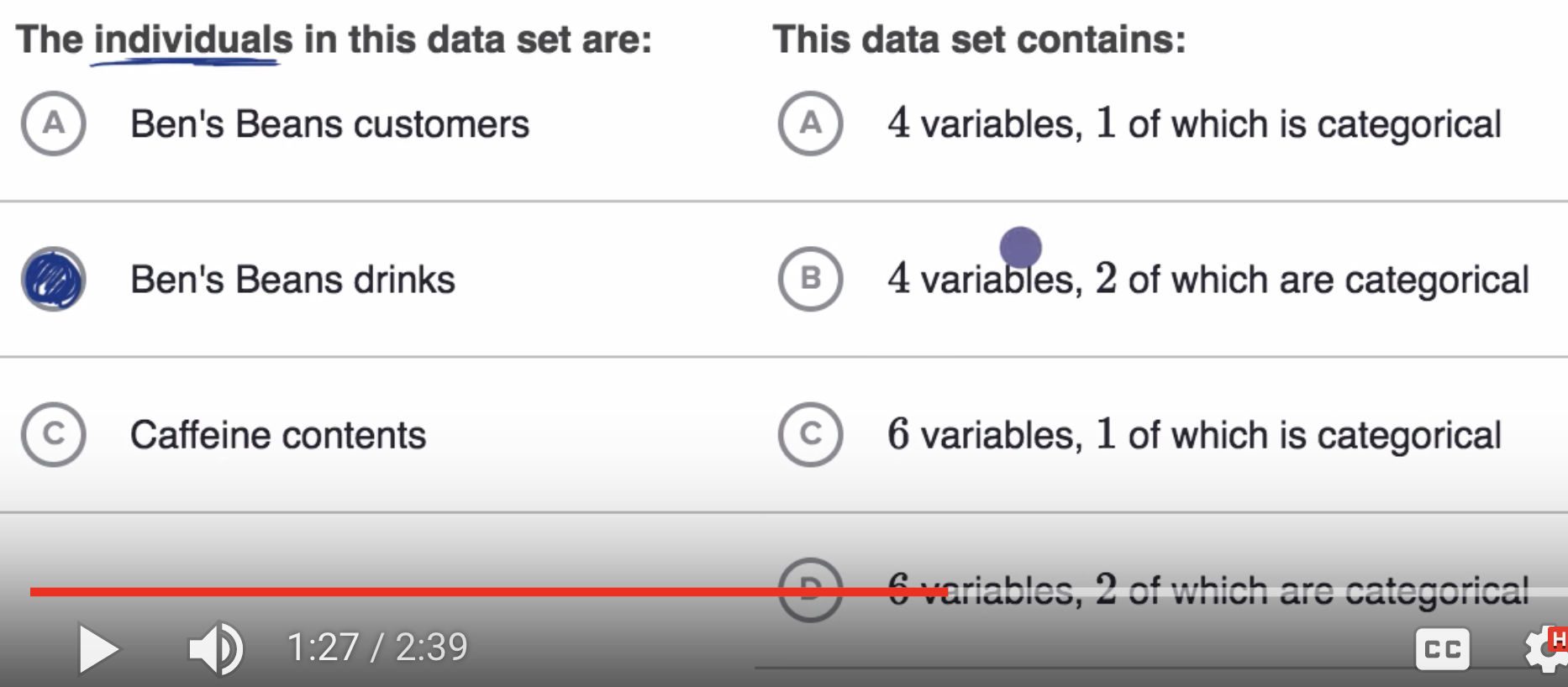
data#
dataset#
dataset = {
"Drink": [
"Brewed coffee",
"Caffe latte",
"Caffe mocha",
"Cappuccino",
"Iced brewed coffee",
"Chai latte",
],
"Type": ["Hot", "Hot", "Hot", "Hot", "Cold", "Hot"],
"Calories": [4, 100, 170, 60, 60, 120],
"Sugars (g)": [0, 14, 27, 8, 15, 25],
"Caffein (mg)": [260, 75, 95, 75, 120, 60],
}
Pandas Dataframe#
df = pd.DataFrame(dataset).set_index("Drink")
df
| Type | Calories | Sugars (g) | Caffein (mg) | |
|---|---|---|---|---|
| Drink | ||||
| Brewed coffee | Hot | 4 | 0 | 260 |
| Caffe latte | Hot | 100 | 14 | 75 |
| Caffe mocha | Hot | 170 | 27 | 95 |
| Cappuccino | Hot | 60 | 8 | 75 |
| Iced brewed coffee | Cold | 60 | 15 | 120 |
| Chai latte | Hot | 120 | 25 | 60 |
Spark Dataframe#
sdf = spark.createDataFrame(zip(*dataset.values()), schema=list(dataset.keys()))
sdf.show()
+------------------+----+--------+----------+------------+
| Drink|Type|Calories|Sugars (g)|Caffein (mg)|
+------------------+----+--------+----------+------------+
| Brewed coffee| Hot| 4| 0| 260|
| Caffe latte| Hot| 100| 14| 75|
| Caffe mocha| Hot| 170| 27| 95|
| Cappuccino| Hot| 60| 8| 75|
|Iced brewed coffee|Cold| 60| 15| 120|
| Chai latte| Hot| 120| 25| 60|
+------------------+----+--------+----------+------------+
Kafka producer#
p = Producer({'bootstrap.servers': bootstrap_servers})
for i in zip(*dataset.values()):
x = dict(zip(dataset.keys(), i))
record_key = str(uuid.uuid4())
record_value = json.dumps(x)
p.produce(topic, value=record_value)
p.poll(0)
p.flush()
0
KSQL stream#
client.create_stream(table_name=topic,
columns_type=['`Drink` string','`Type` string', '`Calories` bigint','`Sugars (g)` bigint', '`Caffein (mg)` bigint'],
topic=topic,
value_format='JSON'
)
res = client.query(f"select * from {topic}")
while True:
try:
print(next(res))
except RuntimeError:
print('')
break
[{"header":{"queryId":"transient_STATS0101E908401_8697743092071727740","schema":"`Drink` STRING, `Type` STRING, `Calories` BIGINT, `Sugars (g)` BIGINT, `Caffein (mg)` BIGINT"}},
{"row":{"columns":["Brewed coffee","Hot",4,0,260]}},
{"row":{"columns":["Caffe latte","Hot",100,14,75]}},
{"row":{"columns":["Caffe mocha","Hot",170,27,95]}},
{"row":{"columns":["Cappuccino","Hot",60,8,75]}},
{"row":{"columns":["Iced brewed coffee","Cold",60,15,120]}},
{"row":{"columns":["Chai latte","Hot",120,25,60]}},
]
Spark stream#
read stream#
df_raw = spark \
.readStream \
.format('kafka') \
.option('kafka.bootstrap.servers', bootstrap_servers) \
.option("startingOffsets", "earliest") \
.option('subscribe', topic) \
.load()
df_raw.printSchema()
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
write stream#
df_json = df_raw.selectExpr('CAST(value AS STRING) as json')
df_json.select(F.from_json(df_json.json, sdf.schema).alias('stream_data')) \
.writeStream \
.queryName(topic) \
.trigger(once=True) \
.format("memory") \
.start() \
.awaitTermination()
spark.sql(f"select * from {topic}").show(truncate=False)
+---------------------------------------+
|stream_data |
+---------------------------------------+
|{Brewed coffee, Hot, 4, 0, 260} |
|{Caffe latte, Hot, 100, 14, 75} |
|{Caffe mocha, Hot, 170, 27, 95} |
|{Cappuccino, Hot, 60, 8, 75} |
|{Iced brewed coffee, Cold, 60, 15, 120}|
|{Chai latte, Hot, 120, 25, 60} |
+---------------------------------------+
Find and Replace#
Panads#
df_fr = df.copy()
df_fr.replace({"Type": {"Hot": 1, "Cold": 0}}, inplace=True)
df_fr
| Type | Calories | Sugars (g) | Caffein (mg) | |
|---|---|---|---|---|
| Drink | ||||
| Brewed coffee | 1 | 4 | 0 | 260 |
| Caffe latte | 1 | 100 | 14 | 75 |
| Caffe mocha | 1 | 170 | 27 | 95 |
| Cappuccino | 1 | 60 | 8 | 75 |
| Iced brewed coffee | 0 | 60 | 15 | 120 |
| Chai latte | 1 | 120 | 25 | 60 |
Spark#
sdf_fr = sdf.withColumn(
"Type", F.when(F.col("Type") == "Hot", 1).when(F.col("Type") == "Cold", 0)
)
sdf_fr.show()
+------------------+----+--------+----------+------------+
| Drink|Type|Calories|Sugars (g)|Caffein (mg)|
+------------------+----+--------+----------+------------+
| Brewed coffee| 1| 4| 0| 260|
| Caffe latte| 1| 100| 14| 75|
| Caffe mocha| 1| 170| 27| 95|
| Cappuccino| 1| 60| 8| 75|
|Iced brewed coffee| 0| 60| 15| 120|
| Chai latte| 1| 120| 25| 60|
+------------------+----+--------+----------+------------+
Label Encoding#
Pandas#
df_lc = df.copy()
df_lc["Type_Hot"] = df_lc["Type"].astype("category").cat.codes
df_lc
| Type | Calories | Sugars (g) | Caffein (mg) | Type_Hot | |
|---|---|---|---|---|---|
| Drink | |||||
| Brewed coffee | Hot | 4 | 0 | 260 | 1 |
| Caffe latte | Hot | 100 | 14 | 75 | 1 |
| Caffe mocha | Hot | 170 | 27 | 95 | 1 |
| Cappuccino | Hot | 60 | 8 | 75 | 1 |
| Iced brewed coffee | Cold | 60 | 15 | 120 | 0 |
| Chai latte | Hot | 120 | 25 | 60 | 1 |
Sklearn#
df_lc = df.copy()
df_lc["Type_Hot"] = preprocessing.LabelEncoder().fit_transform(df["Type"])
df_lc
| Type | Calories | Sugars (g) | Caffein (mg) | Type_Hot | |
|---|---|---|---|---|---|
| Drink | |||||
| Brewed coffee | Hot | 4 | 0 | 260 | 1 |
| Caffe latte | Hot | 100 | 14 | 75 | 1 |
| Caffe mocha | Hot | 170 | 27 | 95 | 1 |
| Cappuccino | Hot | 60 | 8 | 75 | 1 |
| Iced brewed coffee | Cold | 60 | 15 | 120 | 0 |
| Chai latte | Hot | 120 | 25 | 60 | 1 |
Spark#
sdf_lc = StringIndexer(inputCol="Type", outputCol="Type_Cold").fit(sdf).transform(sdf)
sdf_lc.show()
+------------------+----+--------+----------+------------+---------+
| Drink|Type|Calories|Sugars (g)|Caffein (mg)|Type_Cold|
+------------------+----+--------+----------+------------+---------+
| Brewed coffee| Hot| 4| 0| 260| 0.0|
| Caffe latte| Hot| 100| 14| 75| 0.0|
| Caffe mocha| Hot| 170| 27| 95| 0.0|
| Cappuccino| Hot| 60| 8| 75| 0.0|
|Iced brewed coffee|Cold| 60| 15| 120| 1.0|
| Chai latte| Hot| 120| 25| 60| 0.0|
+------------------+----+--------+----------+------------+---------+
One-Hot Encoding#
Pandas#
df_ohc = pd.get_dummies(df, columns=["Type"], prefix="Type")
df_ohc
| Calories | Sugars (g) | Caffein (mg) | Type_Cold | Type_Hot | |
|---|---|---|---|---|---|
| Drink | |||||
| Brewed coffee | 4 | 0 | 260 | 0 | 1 |
| Caffe latte | 100 | 14 | 75 | 0 | 1 |
| Caffe mocha | 170 | 27 | 95 | 0 | 1 |
| Cappuccino | 60 | 8 | 75 | 0 | 1 |
| Iced brewed coffee | 60 | 15 | 120 | 1 | 0 |
| Chai latte | 120 | 25 | 60 | 0 | 1 |
Sklearn#
x = (
preprocessing.OneHotEncoder()
.fit_transform(df["Type"].values.reshape(-1, 1))
.toarray()
)
df_ohc = pd.concat(
[
df.drop(columns="Type").reset_index(),
pd.DataFrame(x, columns=["Type_Cold", "Type_Hot"]),
],
axis=1,
)
df_ohc.set_index("Drink")
| Calories | Sugars (g) | Caffein (mg) | Type_Cold | Type_Hot | |
|---|---|---|---|---|---|
| Drink | |||||
| Brewed coffee | 4 | 0 | 260 | 0.0 | 1.0 |
| Caffe latte | 100 | 14 | 75 | 0.0 | 1.0 |
| Caffe mocha | 170 | 27 | 95 | 0.0 | 1.0 |
| Cappuccino | 60 | 8 | 75 | 0.0 | 1.0 |
| Iced brewed coffee | 60 | 15 | 120 | 1.0 | 0.0 |
| Chai latte | 120 | 25 | 60 | 0.0 | 1.0 |
Spark#
sdf_ohc = (
OneHotEncoder(inputCol="Type_Cold", outputCol="Type_Vec")
.fit(sdf_lc)
.transform(sdf_lc)
)
sdf_ohc.show()
+------------------+----+--------+----------+------------+---------+-------------+
| Drink|Type|Calories|Sugars (g)|Caffein (mg)|Type_Cold| Type_Vec|
+------------------+----+--------+----------+------------+---------+-------------+
| Brewed coffee| Hot| 4| 0| 260| 0.0|(1,[0],[1.0])|
| Caffe latte| Hot| 100| 14| 75| 0.0|(1,[0],[1.0])|
| Caffe mocha| Hot| 170| 27| 95| 0.0|(1,[0],[1.0])|
| Cappuccino| Hot| 60| 8| 75| 0.0|(1,[0],[1.0])|
|Iced brewed coffee|Cold| 60| 15| 120| 1.0| (1,[],[])|
| Chai latte| Hot| 120| 25| 60| 0.0|(1,[0],[1.0])|
+------------------+----+--------+----------+------------+---------+-------------+